2023. 12. 1. 08:53ㆍ머신러닝, 딥러닝/파이토치
📚 RNN을 이용한 KOSPI 주가 예측
코스피 주가 데이터를 이용해서 주가 예측을 실시한다.
📌 데이터/라이브러리 불러오기
|
|
import numpy as np |
|
|
import pandas as pd |
|
|
from sklearn.preprocessing import MinMaxScaler |
|
|
import torch |
|
|
import torch.nn as nn |
|
|
import torch.optim as optim |
|
|
import matplotlib.pyplot as plt |
|
|
|
|
|
from google.colab import drive |
|
|
drive.mount('/content/drive') |
|
|
cd drive/My\ Drive/파이토치 스터디 |
|
|
df = pd.read_csv('kospi.csv') |
|
|
|
|
|
df.head() |

총 413일의 시가, 종가, 최고가, 최저가에 대한 정보를 가지고 있다. 여기서는 종가인 Close 변수를 예측한다.
📌스케일링
|
|
#종가 제외 스케일링 |
|
|
scaler = MinMaxScaler() |
|
|
df[['Open', 'High', 'Low', 'Close', 'Volume']] = scaler.fit_transform(df[['Open','High', 'Low','Close','Volume']]) |
MinMaxScaler를 이용하여 스케일링을 실시한다.
📌Train/Test 분리 및 텐서로 변경
|
|
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') |
|
|
device |

GPU 사용 여부 확인 (코랩 사용)
|
|
#넘파이 배열로 변경 |
|
|
x = df[['Open', 'High', 'Low', 'Volume']].values |
|
|
y = df['Close'].values |
|
|
|
|
|
#시퀀스 데이터 생성 |
|
|
def seq_data(x, y, sequence_length): |
|
|
x_seq = [] |
|
|
y_seq = [] |
|
|
for i in range(len(x) - sequence_length): |
|
|
x_seq.append(x[ i : i + sequence_length]) |
|
|
y_seq.append(y[i + sequence_length]) |
|
|
|
|
|
#gpu용 텐서로 변환 |
|
|
return torch.FloatTensor(x_seq).to(device), torch.FloatTensor(y_seq).to(device).view(-1,1) |
데이터를 우선 numpy 배열로 변경한다.
그리고 train'/test를 분리하기 위한 함수를 정의한다. 여기서 sequence_length 는 time window를 나타낸다.
time window가 3이면 [1,2,3], [2,3,4], [3,4,5] 순으로 3일씩 묶음으로 x 데이터가 구성된다. y 데이터는 각 묶음의 가장 마지막 날 바로 다음 날로 y_seq에 저장한다.
라인13에서 gpu용 텐서로 변환한다. view 부분은 2차원으로 변경하는 것인데, MSE Loss가 기본적으로 2차원 타깃 데이터를 받기 때문이다.
|
|
split = 200 |
|
|
sequence_length=5 |
|
|
x_seq, y_seq = seq_data(x, y, sequence_length) |
|
|
|
|
|
#순서대로 200개는 학습, 나머지는 평가 |
|
|
x_train_seq = x_seq[:split] |
|
|
y_train_seq = y_seq[:split] |
|
|
|
|
|
x_test_seq = x_seq[split:] |
|
|
y_test_seq = y_seq[split:] |
|
|
|
|
|
print(x_train_seq.size(), y_train_seq.size()) |
|
|
print(x_test_seq.size(), y_test_seq.size()) |

순서대로 200개는 학습, 200개는 테스트 셋으로 사용한다.

x_train_seq 데이터를 살펴보면, 5일 단위로 각 변수들의 값이 묶여서 저장되어 있다.
📌배치 형태로 변경
|
|
train = torch.utils.data.TensorDataset(x_train_seq, y_train_seq) |
|
|
test = torch.utils.data.TensorDataset(x_test_seq, y_test_seq) |
|
|
|
|
|
batch_size = 20 |
|
|
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size = batch_size, shuffle=True) |
|
|
test_loader = torch.utils.data.DataLoader(dataset=test, batch_size = batch_size) |
DataLoader를 이용하여 배치 형태로 변경한다.
📌 모델 구축

source : 딥러닝을 위한 파이토치 입문, 딥러닝호형 저
여기서는 위와 같은 구조의 RNN 모델을 생성한다.
|
|
#기본 하이퍼 파라미터 설정 |
|
|
input_size = x_seq.size(2) |
|
|
num_lyaers = 2 |
|
|
hidden_size = 8 |
|
|
class VanillaRNN(nn.Module): |
|
|
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device): |
|
|
super(VanillaRNN, self).__init__() |
|
|
self.device = device |
|
|
self.hidden_size = hidden_size |
|
|
self.num_layers = num_layers |
|
|
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) #한 줄로 모델 정의 |
|
|
self.fc = nn.Sequential(nn.Linear(hidden_size * sequence_length, 1), nn.Sigmoid()) #RNN 층에서 나온 결과를 fc 층으로 전달해서 예측값 계산 |
|
|
|
|
|
def forward(self, x): |
|
|
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device) #초기값 0으로 설정 |
|
|
out,_ = self.rnn(x, h0) |
|
|
out = out.reshape(out.shape[0], -1) |
|
|
out = self.fc(out) |
|
|
return out |
파이토치에서는 라인7에서와 같이 한 줄로 RNN 모델을 정의할 수 있다.
nn.RNN의 원래 입력 형태는 길이x배치사이즈x변수 크기 이기 때문에 현재 (200,5,4) 크기의 데이터를 (5,200,4) 로 변경해야 하지만, 여기서는 batch_first 옵션을 사용하여 그대로 이용하였다.
라인11 :
RNN에는 이전 단계의 hidden vector가 다시 입력되는데, 맨 처음 단계에서는 이것이 존재하지 않으므로 0으로 된 값을 전달한다
라인12:
맨 처음 time step에는 초기 벡터인 h0을 직접 전달한다.
라인13 :
self.rnn 을 사용한다. 여기서는 many to many 방식으로 각 시간에 대한 예측값과 hidden vector를 계산한다.
여기서는 은닉 상태는 사용하지 않고 예측값만 받기 위해서 _ 를 사용했다.
라인14:
모든 출력값을 1차원으로 만들어서 self.fc에 넣는다.
📌정의한 RNN 모델 불러오기
|
|
model = VanillaRNN(input_size=input_size, |
|
|
hidden_size = hidden_size, |
|
|
sequence_length=sequence_length, |
|
|
num_layers=num_layers, |
|
|
device=device).to(device) |
앞서 정의한 모델을 불러온다. GPU 연산을 위해서는 마지막에 to(device)를 입력해야 함.
📌 손실함수 및 최적화 방법 정의
|
|
criterion = nn.MSELoss() |
|
|
num_epochs = 301 |
|
|
optimizer = optim.Adam(model.parameters(), lr=1e-3) |
MSE를 손실함수로 사용하고, 에폭은 301, Adam 옵티마이저를 사용함
📌모델 학습
|
|
loss_graph = [] |
|
|
n = len(train_loader) |
|
|
|
|
|
for epoch in range(num_epochs): |
|
|
running_loss = 0 |
|
|
|
|
|
for data in train_loader: |
|
|
seq, target = data #배치 데이터 |
|
|
out = model(seq) #출력값 계산 |
|
|
loss = criterion(out, target) #손실함수 계산 |
|
|
|
|
|
optimizer.zero_grad() |
|
|
loss.backward() |
|
|
optimizer.step() #최적화 |
|
|
running_loss += loss.item() |
|
|
|
|
|
loss_graph.append(running_loss/n) |
|
|
if epoch % 100==0: |
|
|
print('[epoch : %d] loss: %.4f' %(epoch, running_loss/n)) |
|
|
plt.figure(figsize=(20,10)) |
|
|
plt.plot(loss_graph) |
|
|
plt.show() |

일반적인 지도학습과 동일한 방식으로 학습을 진행한다. train set의 loss를 확인하면 올바르게 학습이 진행된 것을 확인할 수 있다.
📌실제값과 예측값 그래프로 비교
|
|
concatdata = torch.utils.data.ConcatDataset([train, test]) |
|
|
data_loader = torch.utils.data.DataLoader(dataset = concatdata, batch_size = 100) |
|
|
|
|
|
with torch.no_grad(): |
|
|
pred = [] |
|
|
model.eval() |
|
|
for data in data_loader: |
|
|
seq, target = data |
|
|
out = model(seq) |
|
|
pred += out.cpu().tolist() |
라인1:
train, test 데이터를 하나의 그래프로 이어서 보기 위해서 concat
라인4~:
예측값을 저장할 빈 텐서 pred를 만들고, 순차적으로 리스트를 저장하면서 이어붙인다.
|
|
plt.figure(figsize = (20,10)) |
|
|
plt.plot(np.ones(100)*len(train), np.linspace(0,1,100), '--', linewidth=0.6) |
|
|
plt.plot(df['Close'][sequence_length:].values,'--') |
|
|
plt.plot(pred, 'b', linewidth = 0.6) |
|
|
plt.legend(['train_boundary','actual','prediction']) |
|
|
plt.show() |
라인2:
train/test를 분리하는 선 그리기

전반적으로 train set 부분은 학습이 잘 진행된 것을 확인할 수 있다. test set 부분에서는 급락 또는 급등하는 부분에서 완벽하게 변곡점을 예측하지 못하는 것을 알 수 있고, 일부 오른쪽으로 shift 된 것을 확인할 수 있다.
📚 LSTM
📌모델 정의
동일한 데이터를 사용해서 LSTM 으로 예측을 실시한다. 기본적인 전처리와 배치 형태로 만드는 단계까지 앞선 RNN 과 동일하다.
|
|
#하이퍼 파라미터 정의 |
|
|
input_size = x_seq.size(2) |
|
|
num_layers = 2 |
|
|
hidden_size = 8 |
|
|
class LSTM(nn.Module): |
|
|
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device): |
|
|
super(LSTM, self).__init__() |
|
|
self.device = device |
|
|
self.hidden_size = hidden_size |
|
|
self.num_layers = num_layers |
|
|
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first = True) |
|
|
self.fc = nn.Linear(hidden_size*sequence_length ,1) |
|
|
|
|
|
def forward(self, x): |
|
|
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device) |
|
|
c0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device) |
|
|
out, _ = self.lstm(x,(h0,c0)) |
|
|
out = out.reshape(out.shape[0], -1) |
|
|
out = self.fc(out) |
|
|
return out |
라인 7:
RNN과 동일하게 파이노치에서는 한 줄로 LSTM 모델을 정의할 수 있다.
라인11, 12:
time step=0의 은닉 상태와 셀 상태를 0으로 입력한다.
|
|
model = LSTM(input_size = input_size, |
|
|
hidden_size=hidden_size, |
|
|
sequence_length=sequence_length, |
|
|
num_layers = num_layers, |
|
|
device=device).to(device) |
모델을 불러온다.
📌 손실함수 및 최적화 방법 정의
|
|
criterion = nn.MSELoss() |
|
|
num_epochs =401 |
|
|
optimizer = optim.Adam(model.parameters(), lr=1e-3) |
📌 모델 학습
|
|
loss_graph = [] |
|
|
n = len(train_loader) |
|
|
|
|
|
for epoch in range(num_epochs): |
|
|
running_loss = 0.0 |
|
|
|
|
|
for data in train_loader: |
|
|
|
|
|
seq, target = data # 배치 데이터 |
|
|
out = model(seq) |
|
|
loss = criterion(out, target) |
|
|
|
|
|
optimizer.zero_grad() |
|
|
loss.backward() |
|
|
optimizer.step() |
|
|
running_loss += loss.item() |
|
|
|
|
|
loss_graph.append(running_loss/n) |
|
|
if epoch % 100 == 0: |
|
|
print('[epoch: %d] loss: %.4f' %(epoch, running_loss/n)) |
📌 예측 실시 후 그래프로 비교 1
|
|
concatdata = torch.utils.data.ConcatDataset([train, test]) |
|
|
data_loader = torch.utils.data.DataLoader(dataset=concatdata, batch_size=100, shuffle=False) |
|
|
|
|
|
with torch.no_grad(): |
|
|
pred = [] |
|
|
model.eval() |
|
|
for data in data_loader: |
|
|
seq, target = data |
|
|
out = model(seq) |
|
|
pred += out.cpu().tolist() |
|
|
|
|
|
plt.figure(figsize=(20,10)) |
|
|
plt.plot(np.ones(100)*len(train),np.linspace(0,1,100),'--', linewidth=0.6) |
|
|
plt.plot(df['Close'][sequence_length:].values,'--') |
|
|
plt.plot(pred,'b', linewidth=0.6) |
|
|
plt.legend(['train boundary','actual','prediction']) |
|
|
plt.show() |
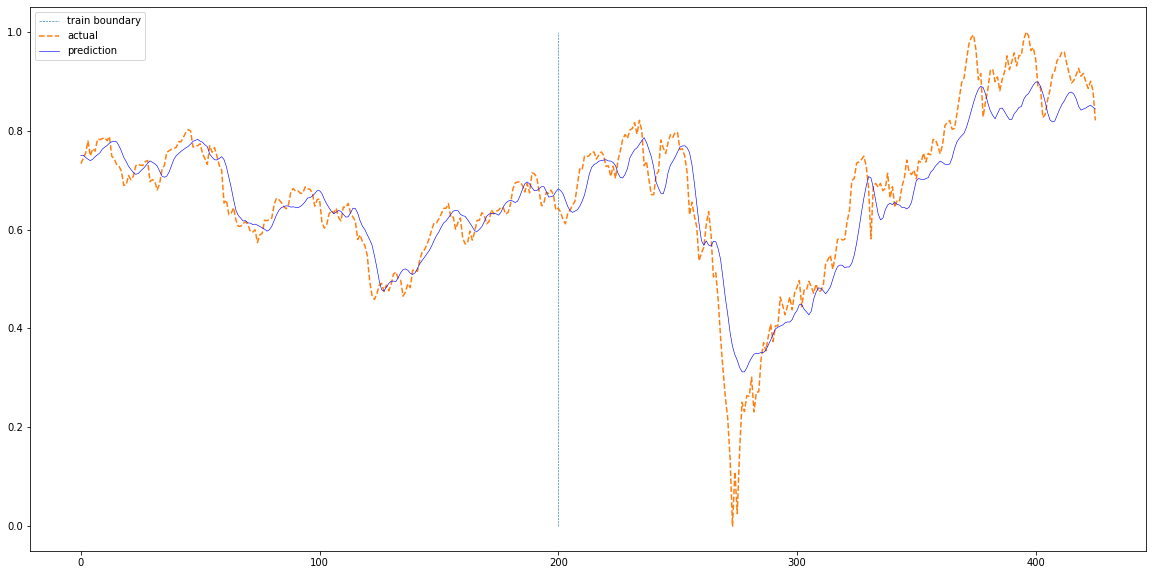
RNN에 비해서 일부 구간에서는 개선된 성능을 확인할 수 있었으나, 급등/급락 장의 예측에는 취약하다.
📚 Reference
딥러닝을 위한 파이토치 입문, 딥러닝호형 저, 영진닷컴
'머신러닝, 딥러닝 > 파이토치' 카테고리의 다른 글
| [PyTorch] AlexNet (0) | 2023.12.01 |
|---|---|
| [PyTorch]신경망으로 회귀분석 / Cross Validation (0) | 2023.12.01 |
| [PyTorch] 기본 개념 (0) | 2023.12.01 |